- Published on
OptimisingLock Free Queues Beyond 50 Million Transaction/S
- Authors

- Name
- Ritu Raj
- @rituraj12797
Hey there!!! In the last blog Lock Free Queues In C++ we discussed the internals of how we implement lock-free queues using ring buffers, but the throughput did not justify the efforts we put in. In this blog, I tried to dive deep into how I optimized the structure and tweaked the algorithms to improve the performance by 5-fold in read (pop) and write (push). The general way I try to explain things is by first discussing what we need to do and why we need to do it. So, beginning with the why's of this.
Why Optimize?
The lock-free queue we just built in the last part was a component needed in one of my projects, which is supposed to be extremely efficient and work in low-latency environments. To give you an example, here is how the system looks from a high level:
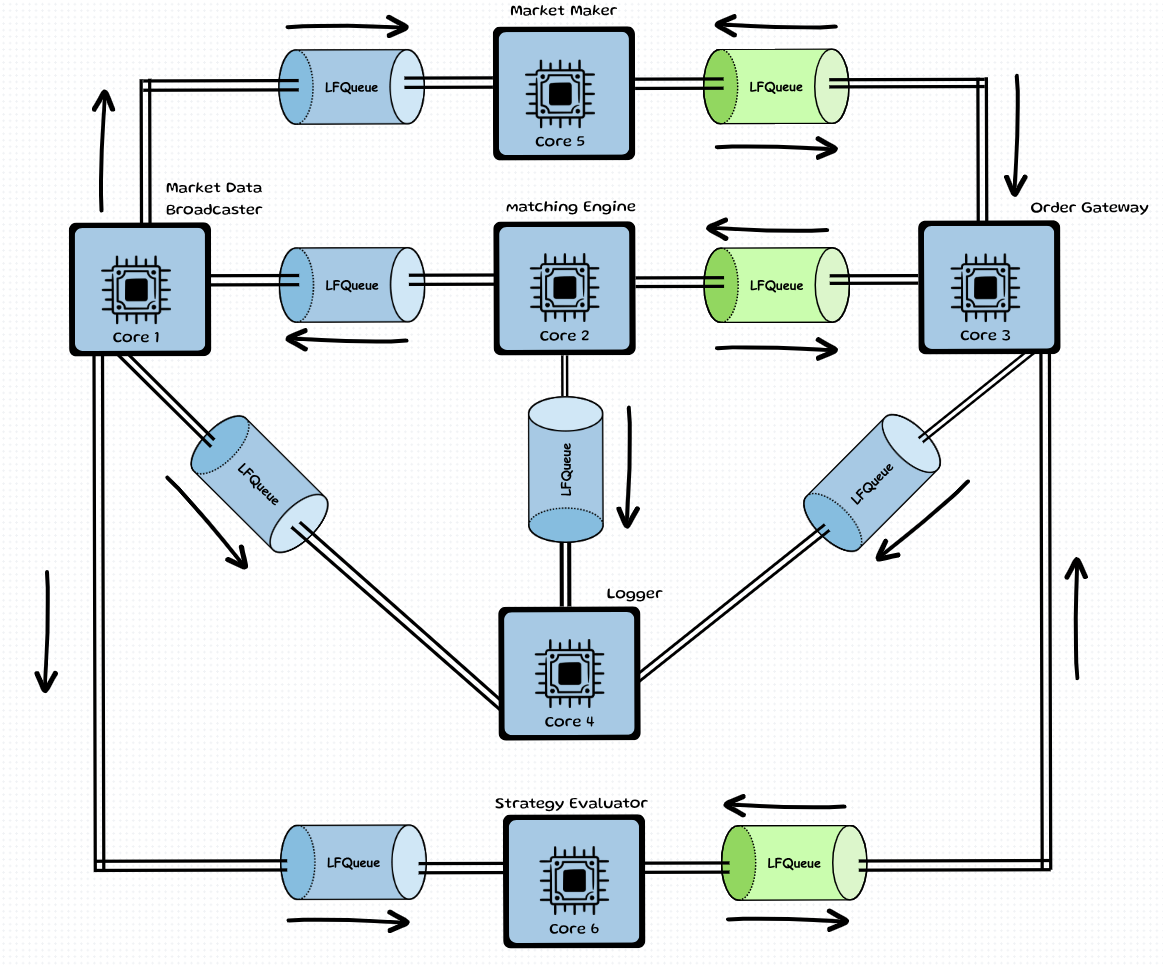
The system is closely coupled, with each component pinned to a different CPU core. These components/threads communicate with each other via this lock-free queue.
Notice how this system is using 12 of these LFQs ( Green Ones represent bi directional lock free queues which are implemented by using 2 unidirectional ones' internally)? Say if data needs to travel from Comp 6 → Comp 3 → Comp 2 → Comp 1 → Comp 6; it needs to go through 4 threads, and in total 4 LFQs. Now, the total time for the data to just get inside these queues and then get popped out from them will be = (read_latency + write_latency).
Total Time = Time (ingestion + extraction) = 4(read_latency + write_latency)
If we compute this for our naive implementation this results in 4(77 + 83) ns = 640 nanoseconds. This means 640 ns is just the cost of data/messages flowing through these channels (assuming the components do their work in 0 ns, which let’s be honest is pure science fiction). Once we add the actual processing overhead, we’re pretty much doomed to end up in the microsecond latency range. So, in order to minimize this overall latency, we try to optimize what we have in our hands: the lock-free queues.
What To Optimize?
If we look into the code of this data structure, we can see that there are 2 things we can work on:
- The wrap-around using modulo.
- Cache Invalidation and Bus traffic.
The Wrap-Around Logic
To increment the indices and wrap them around the buffer, we use the modulo operator. But the modulo operator is extremely costly as it uses the division operation and easily takes around 40 to 60 CPU cycles (not accurate but indicative).
Since we use this in both read and write, the latency multiplies by 2, and sometimes by 3, simply due to the time spent on computation.
The Cache Invalidation and Bus Traffic Problem.
This is the big one. There are two main issues here:
- False Sharing: The variables may be present on the same cache line.
- Ping Pong Effect: The bus snooping problem arises regarding how at each step one core cancels the cache validity of the other.
How to Optimize
1. The Wrap-Around Logic (Replacing Modulo Operation)
So, we will first look into how we are going to optimize the wrap-around logic (if the pointer points to the last index, the net update will make it point to the 0th index).
I will assume that you already know how a modulo operator works: x mod y simply results in the remainder we obtain after dividing x by y.
So why is the modulo operator a problem? Well, because it takes 30 to 40 CPU cycles on average (indicative purpose only, exact numbers may vary). We can optimize it to a single CPU cycle.
Damn!!! But how?? The answer is very simple: using bitwise & (AND). How? We will look through an example.
Below is a table, just have a look at it:
| Index | (Index + 1) % size | (Index+1) & (7) |
|---|---|---|
| 0 | (1)%8 = 1 | 1 & 7 = 1 |
| 1 | (2)%8 = 2 | 2 & 7 = 2 |
| 2 | (3)%8 = 3 | 3 & 7 = 3 |
| 3 | (4)%8 = 4 | 4 & 7 = 4 |
| 4 | (5)%8 = 5 | 5 & 7 = 5 |
| 5 | (6)%8 = 6 | 6 & 7 = 6 |
| 6 | (7)%8 = 7 | 7 & 7 = 7 |
| 7 | (8)%8 = 0 | 8 & 7 = 0 |
| 8 | (9)%8 = 1 | 9 & 7 = 1 |
| 9 | (10)%8 = 2 | 10 & 7 = 2 |
| ... | ... | ... |
| 14 | (15)%8 = 7 | 15 & 7 = 7 |
Surprisingly, the modulo-based incrementor and & based incrementor are behaving the same way, right? There is logic behind this.
A number of the form 2^y - 1 has all of its bits from the MSB to the LSB set as 1. We will call this number a mask. So it kind of acts as a limiter. You perform bitwise AND of the mask with any other number x, and (if x <= mask) it will result in the same number x.
But if you do a bitwise AND with a number x which is > mask, then when we do x & mask, all the bits of the result will be 0 before the MSB of the mask (as those bits are set as 0 in the mask), and the rest of the bits will stay as they are. So it effectively slashes the bits after MSB and the number results in the wrapped form.
So effectively what we can do is: we set the size of our buffer equal to a power of 2. Say we keep it as 2^20, so we define
mask = 2^20 - 1
Incrementing index → (index+1) % size is strictly mathematically equivalent to index → (index+1) & mask. The difference is that bitwise operations happen in a single CPU cycle, saving us tons of time.
2. Addressing the Bus Traffic Problem
Now to the main problem. This section involves some concepts around Bus Snooping, Cache Coherence, the MESI protocol, and understanding L1/L2/L3 cache structures. I would suggest you go through this awesome lecture: YT Link. Also, you should know about the structure of the L1 cache inside the CPU how data is stored and read from the cache in the form of "lines" and not individual variables. Link: Algorithmica Cache Lines.
Okay, we start now. Let us have a look at our current code:
class LFQueue final { // final keyword means no other class inherits this, helping compiler devirtualization ==> performance gains
private :
std::vector<T> store_;
std::atomic<size_t> next_index_to_read = {0};
std::atomic<size_t> next_index_to_write = {0};
public :
explicit LFQueue(std::size_t capacity ) : store_(capacity, T()){
// explicit used here to prevent any auto type conversion
// initialized the queue with a certain capacity
}
// delete extra constructors
LFQueue() = delete;
LFQueue(const LFQueue&) = delete;
LFQueue(const LFQueue&&) = delete;
LFQueue& operator = (const LFQueue&) = delete;
LFQueue& operator = (const LFQueue&&) = delete;
auto getNextWriteIndex() noexcept {
// If queue is full return nullptr
return (((next_index_to_write + 1)%store_.size()) == next_index_to_read ? nullptr : &store_[next_index_to_write]);
}
auto updateWriteIndex() noexcept {
// No contention here as our queue is SPSC ==> Single Producer Single Consumer
// Only one writer, so only it will update the write index
internal_lib::ASSERT(((next_index_to_write + 1)%store_.size()) != next_index_to_read ," Queue full thread must wait before further writing");
next_index_to_write = (next_index_to_write + 1)%(store_.size());
// Simple operation, not atomic, but safe because single writer.
}
auto getNextReadIndex() noexcept {
// If consumer consumed all values and points to next write index ==> no data yet, return nullptr
return (next_index_to_read == next_index_to_write ? nullptr : &(store_[next_index_to_read]));
}
auto updateNextReadIndex() noexcept {
internal_lib::ASSERT(next_index_to_read != next_index_to_write," Nothing to consume by thread ");
next_index_to_read = (next_index_to_read + 1)%(store_.size());
}
};
As you can see here, we have 2 atomic variables: next_index_to_read and next_index_to_write. Since they are atomic integers, they take 8 bytes of memory. An L1 cache line is generally 64 Bytes. Since these 2 variables lie next to each other in memory, they most likely sit in the same cache line.
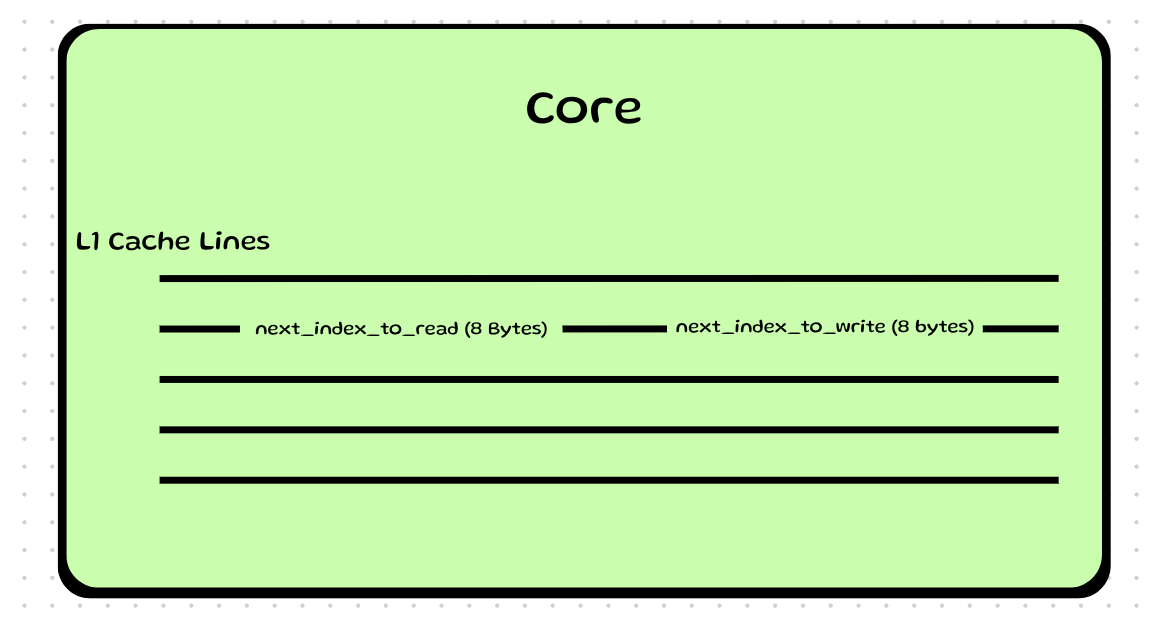
Now notice that we have 4 functions related to these 2 variables:
- getNextReadIndex() → returns the next index to read from.
- getNextWriteIndex() → returns the next index to write to.
- updateNextReadIndex() → update the read index.
- updateWriteIndex() → update the write index.
Consider how we use this LF queue: we have 2 threads (producer and consumer). The consumer thread is pinned on Core 1 and the producer thread is pinned on Core 2.
Means Core 1 (consumer) accesses getNextReadIndex and updateNextReadIndex, and Core 2 (producer) has access to getNextWriteIndex and updateWriteIndex.
However, all of these functions need both of these atomic variables whenever they execute. This means Core 1 and Core 2 store both variables in their L1 cache.
(I would strongly suggest you know about bus snooping as this part uses that understanding extensively).
Where is the problem?? Here it is.
The MESI Cycle of Doom
Step 1: When Core 1 reads an entry from the ring buffer, it calls updateNextReadIndex(). This updates next_index_to_read. It sends an Invalidate signal to all cores which use this variable, and screams: "Invalidate your cache line which contains this variable!" (MESI protocol).
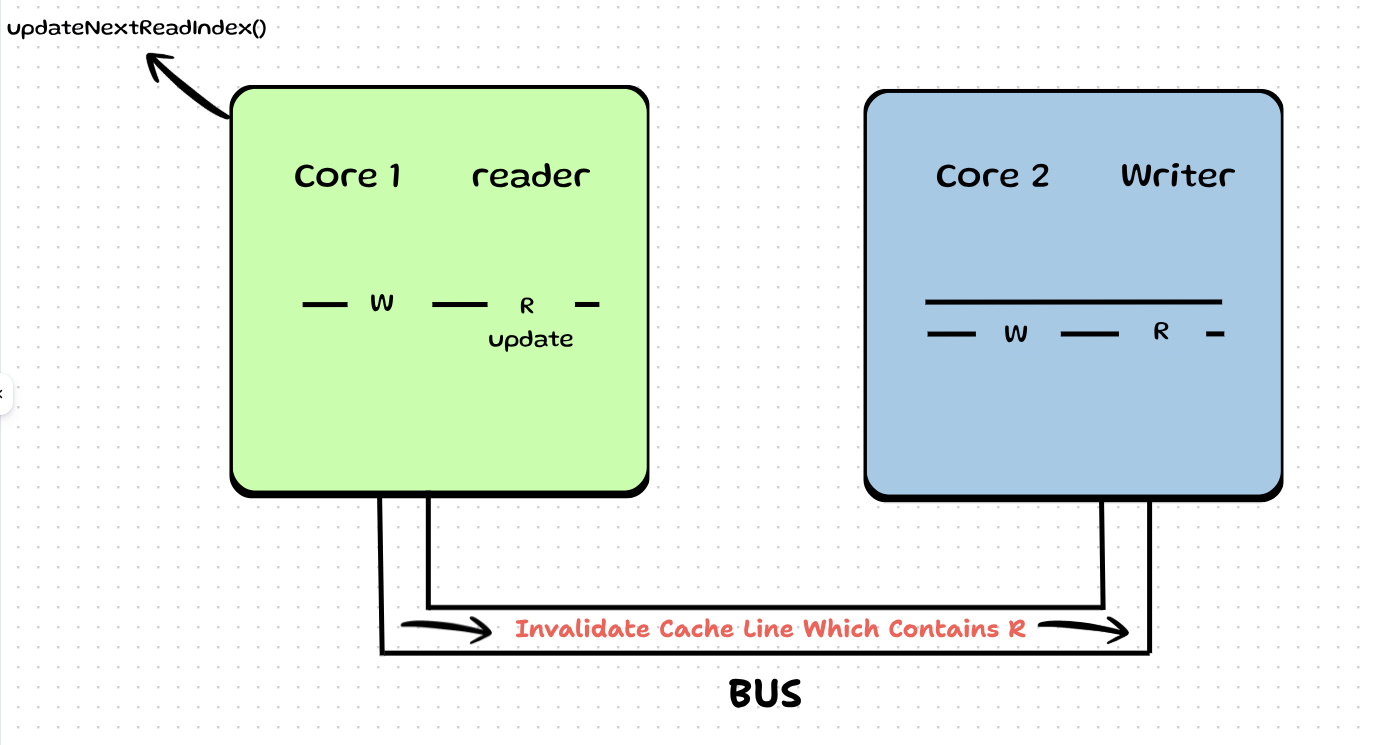
Step 2: This invalidate signal is picked up by Core 2. It sees its 2nd L1 line contains this variable, so it invalidates this whole cache line. Remember that next_index_to_write also lay on this line! So because the line is invalid, that variable's cache is also invalidated.
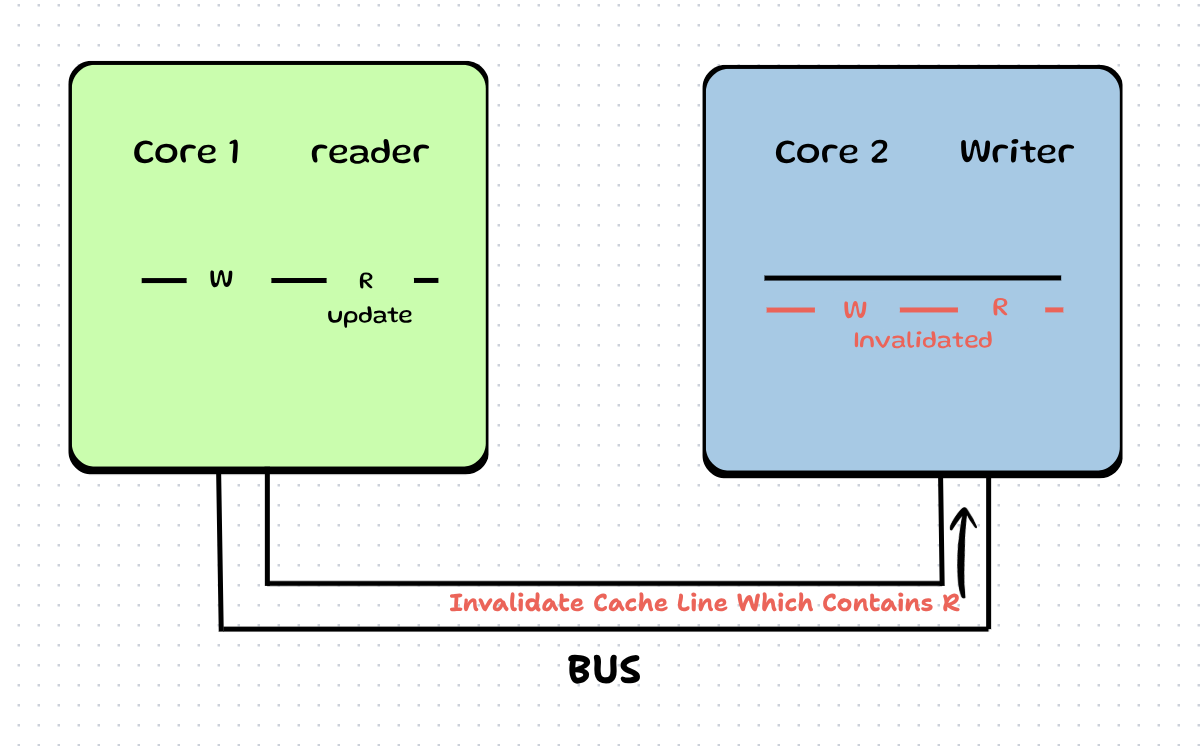
Step 3: Core 1 now updates the value of next_index_to_read and now it snoops the CPU bus to look for any request of variables lying on its 1st L1 cache line.
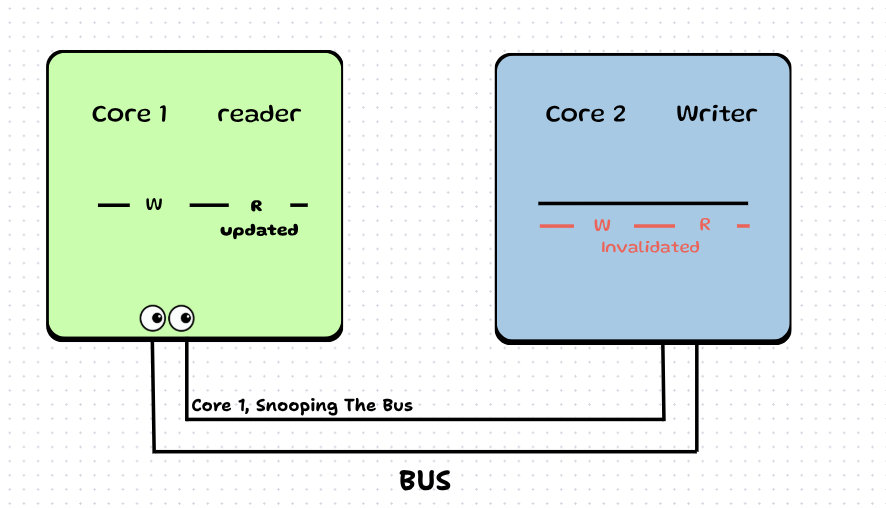
Step 4: Now say Core 2 (the producer) needs to write something. It sees that next_index_to_write is invalidated.
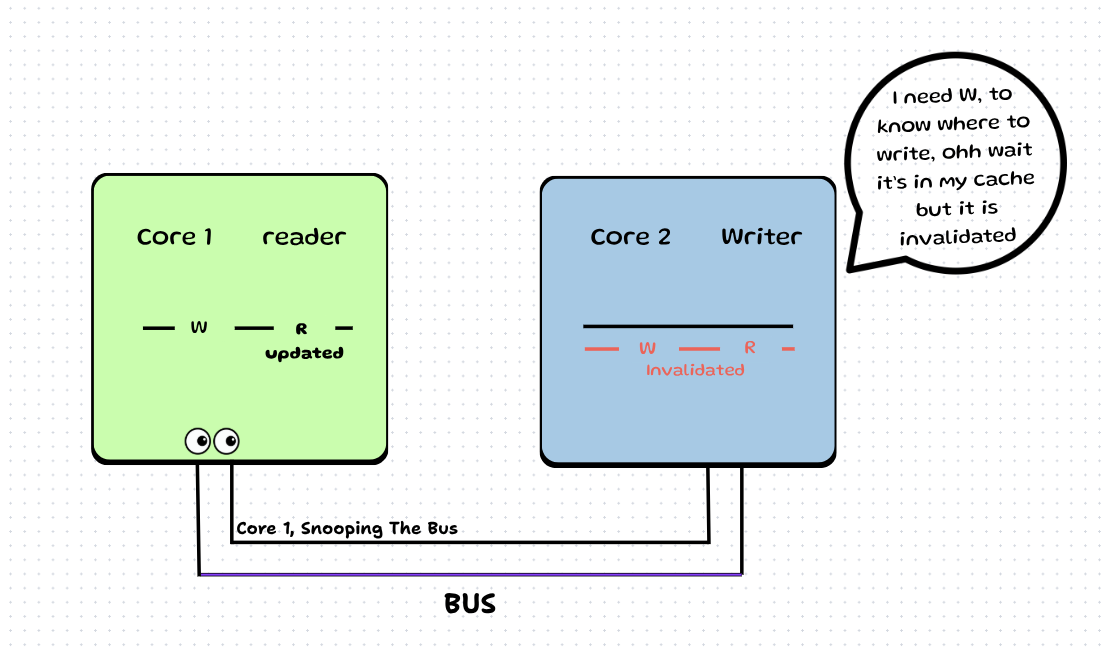
Step 5: It sends a read request to the bus to get the updated value of next_index_to_write.
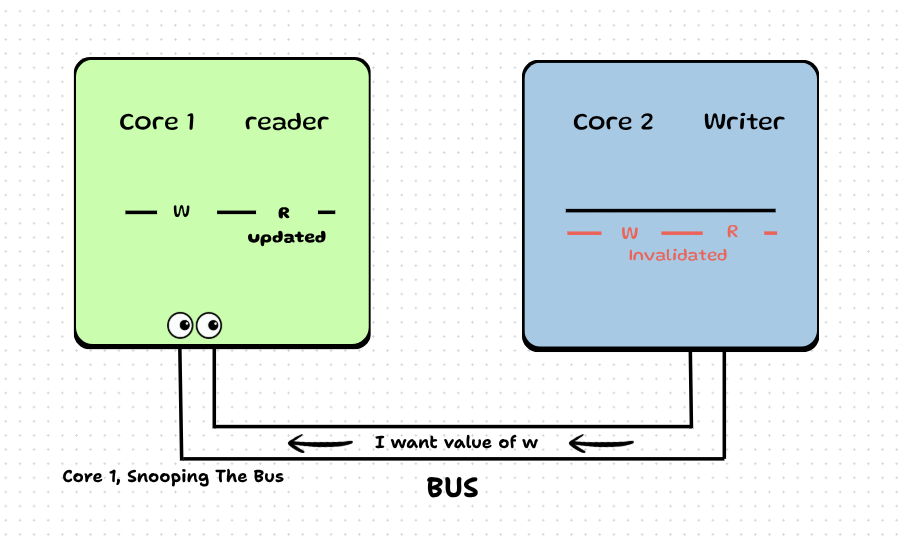
Step 6: Core 1, which was snooping the bus, catches this request and sends the value to Core 2 via the Bus.
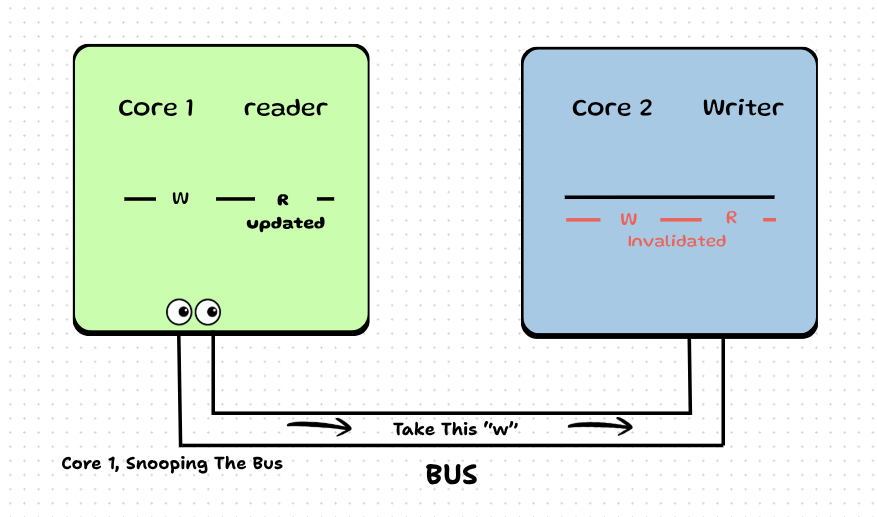
Now you might be wondering: next_index_to_write wasn't modified, so why was it invalidated? Simply because it was lying on the same cache line as next_index_to_read.
Step 7: Now that Core 2 has the correct index, it writes to the queue and calls updateWriteIndex(), which updates next_index_to_write and sends an Invalidate signal to all cores.
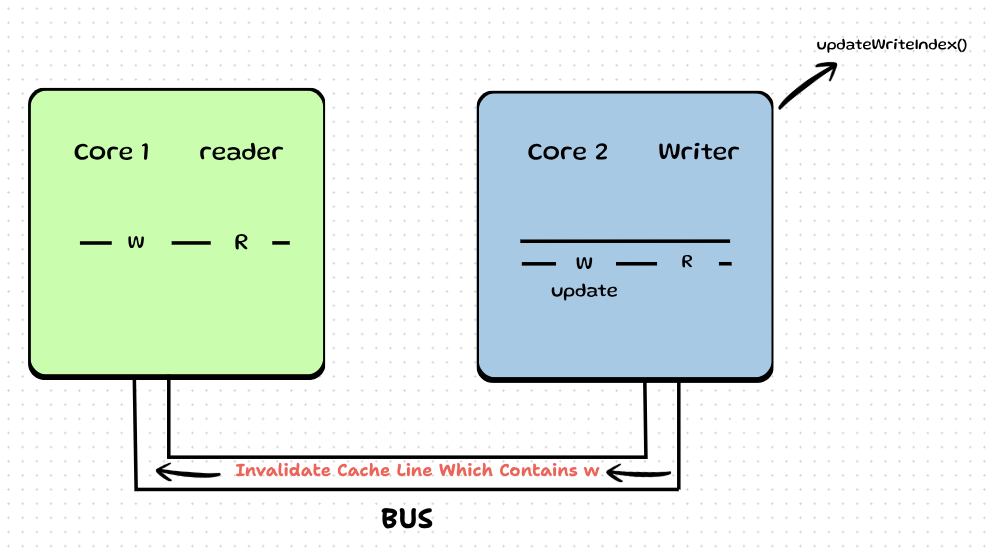
Step 8: Core 1 catches this signal and invalidates its L1 cache line which contains next_index_to_write (and tragically, next_index_to_read too).
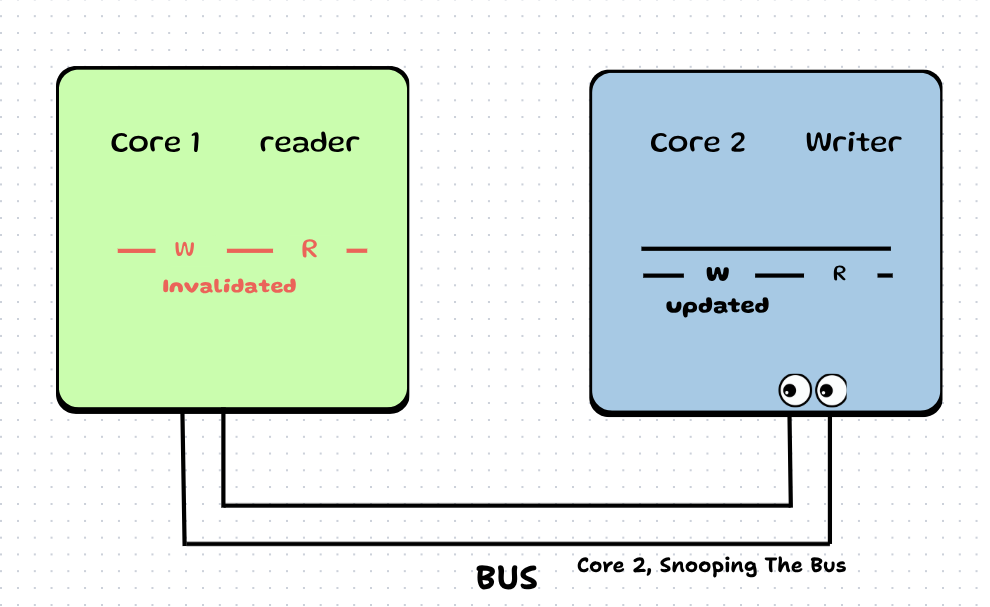
Step 9: Now say consumer again tries to consume. It sees its cache is invalidated, so it sends a read request on the bus.
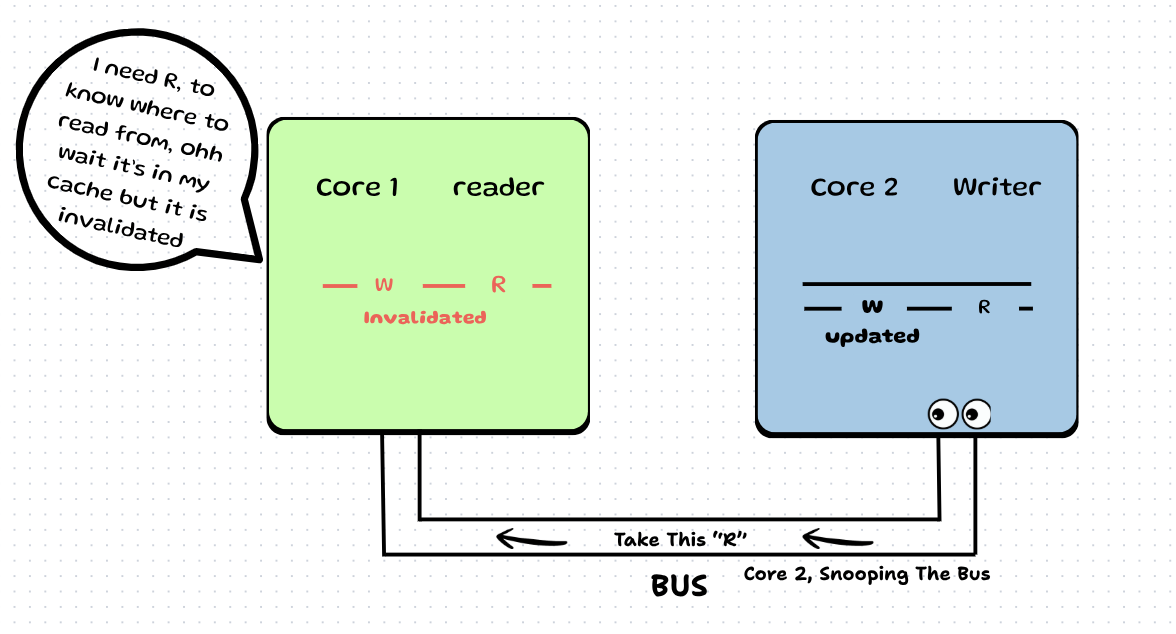
Step 10: Core 2 snoops this request and sends the data to Core 1.
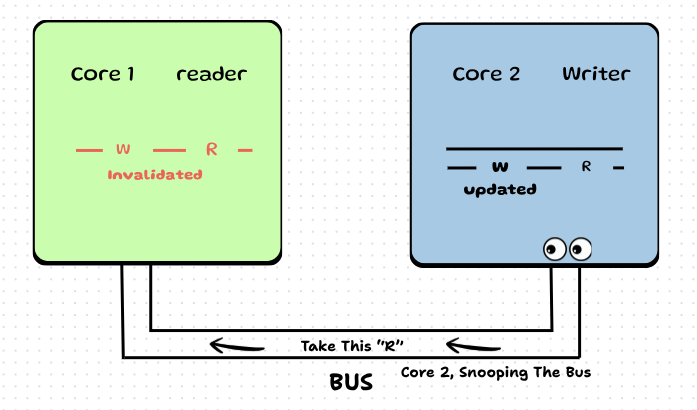
And The Cycle Continues Again from Step 1.
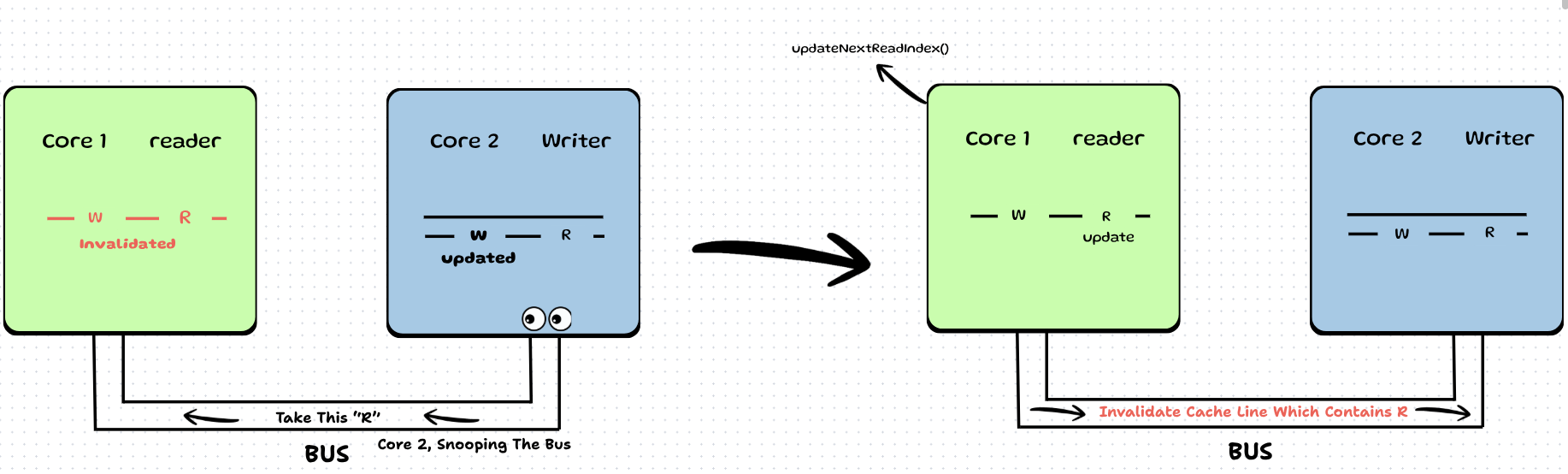
And the cycle continues!
- When reader consumes → it invalidates writer's cache.
- When writer needs to write → it hits the bus to fetch data.
- When writer writes → it invalidates reader's cache.
- When reader needs to read → it hits the bus to fetch data.
So what is the core problem? False Sharing. The writer is invalidating the read index, and the reader is invalidating the write index.
Fix 1 : We define the atomic variables to be of 64 bytes so that they are guaranteed to lie on different cache lines. Since the size of an L1 cache line is typically 64 bytes, padding them ensures separation.
code :
alignas(64) std::atomic<size_t> next_index_to_read = {0};
alignas(64) std::atomic<size_t> next_index_to_write = {0};
This makes sure that the variables sit in L1 cache something like this:
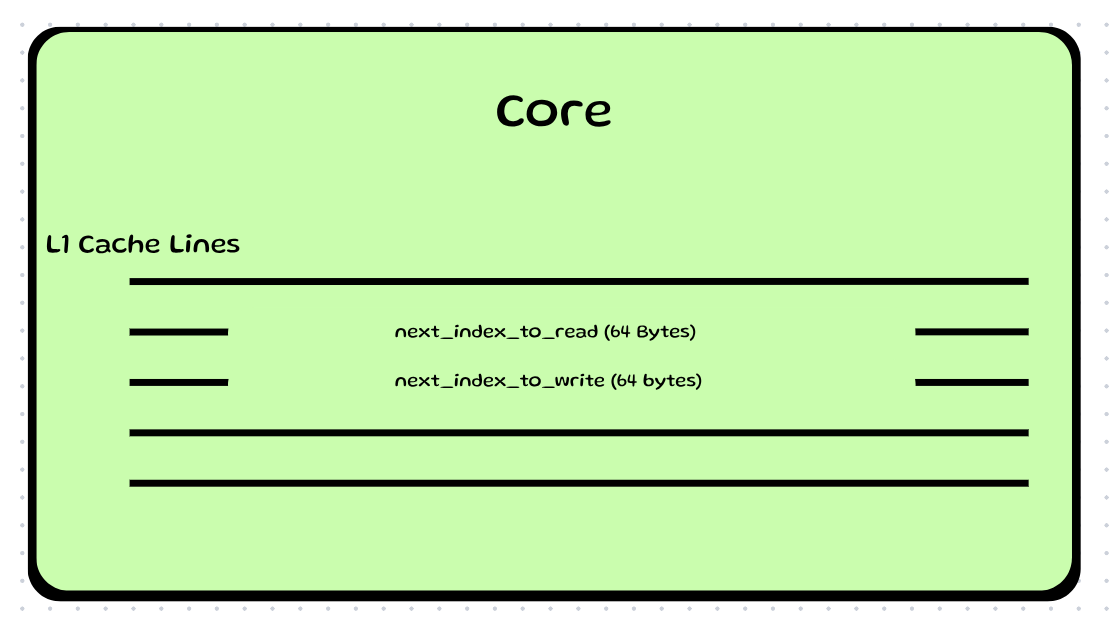
How will this help?
Now, let's replay our scenario:
Step 1: Core 1 (Consumer) reads a value and calls updateNextReadIndex(). It modifies next_index_to_read.
- The Change: It sends an invalidation signal ONLY for Cache Line X.
- The Result: Core 2 (Producer) sees the signal. It checks its cache. "Do I have Line X? Yes. Okay, invalidating Line X."
- The Magic: Core 2's Line Y (which holds next_index_to_write) remains VALID. It is untouched!
Step 2: Core 2 (Producer) wants to write data. It calls getNextWriteIndex().
- The Change: It reads next_index_to_write from Line Y.
- The Result: Since Line Y was never invalidated, this is a L1 Cache Hit. It takes ~1 nanosecond. Instant. No bus snooping required for this variable.
Step 3: Core 2 writes data and calls updateWriteIndex(). It modifies next_index_to_write.
- The Change: It invalidates Line Y.
- The Result: Core 1 invalidates its copy of Line Y. But Core 1's Line X (holding next_index_to_read) stays valid.
Step 4: Core 1 calls getNextReadIndex().
- The Change: It reads next_index_to_read from Line X.
- The Result: L1 Cache Hit.
By simply adding alignas(64), we completely stopped the Producer and Consumer from stepping on each other's toes when they are just minding their own business (updating their own indices). This eliminates "False Sharing" and gives us a nice performance bump.
But... We Are Not Done Yet, you might think, "Great! Zero bus traffic!" Unfortunately, no. We still have a massive problem.
Look at the code for updateWriteIndex() again:
auto updateWriteIndex() noexcept {
// WAIT! We are reading 'next_index_to_read' here!
internal_lib::ASSERT(((next_index_to_write + 1) % size) != next_index_to_read, "Queue full");
next_index_to_write = (next_index_to_write + 1) % size;
}
Do you see it? To check if the queue is full, the Producer (Core 2) has to read next_index_to_read. But who owns next_index_to_read's valid cache? The Consumer (Core 1). So, even though we separated the lines:
Consumer updates read_index (Invalidates Core 2's copy of Line X).
Producer wants to check "Is Queue Full?".
Producer tries to read read_index. CACHE MISS.
Producer has to snoop the bus and drag the value all the way from Core 1.
This is called True Sharing. We actually need the value from the other core. This "Ping-Pong" of the cache line across the bus takes ~20-40 nanoseconds.
means the update function still causes bus traffic by the "Ping Pong" effect.
Well... How do we fix this?? This was a difficult thing to find on the internet, but somehow I luckily ended up on an awesome article by The Bearded Sage titled "True Sharing, False Sharing and Ping-Ponging" (It's http and not https, so visit at your own risk). Also, there are some Slides on it from the famous Lecture I linked above
Fix 2: The "Lazy Pointer" (Shadow Indices)
Okay, so we fixed the False Sharing using alignas(64). But we still have a "Traffic" problem. To understand why, we need to look at the geometry of a Ring Buffer.
The Problem: Being "Too" Up-To-Date
Imagine the Producer (Writer) is at index W and the Consumer (Reader) is at index R. The Producer's #1 rule is: "Do not write if the queue is full." Mathematically, "Full" means:
(W + 1) % mod == R.
In our naive code, the Producer asks the Consumer: "Hey, where are you exactly?" (read_index.load()) before every single write.
- Write 1: "Where are you?" → "I'm at 50." → "Okay, I write to 1."
- Write 2: "Where are you?" → "I'm at 50." → "Okay, I write to 2."
- Write 3: "Where are you?" → "I'm at 51." → "Okay, I write to 3."
Every time the Producer asks "Where are you?", it forces a bus transaction if the Consumer has updated the index. This is expensive. We don't need to know exactly where the Reader is. We just need to know if it is here (where we are going to write) or not.
The Logic: The "Safe Zone"
We know that the Reader can never "jump" past the Writer. It can only chase it. This creates two scenarios for free space:
Scenario A: Writer is behind Reader
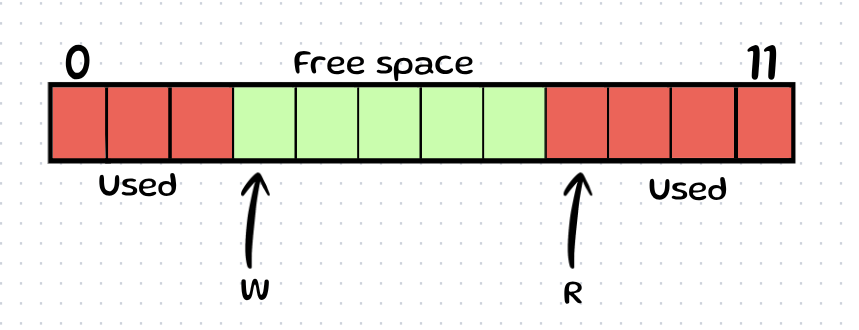
Here, the Writer is at W. The Reader is at R. We know for a fact that indices W to R-1 are Empty. We can safely write into this "Safe Zone" without checking on the Reader again!
Scenario B: Reader is behind Writer (Wrap Around)
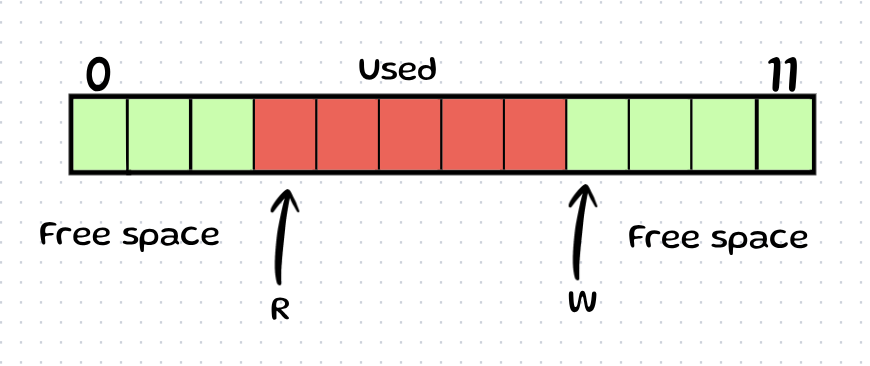
Here, the Writer has wrapped around. We know that W to Last is free, AND 0 to R-1 is free. Again, we have a massive chunk of space we can fill blindly.
The Solution: Shadow Indexing
The Producer maintains a local variable: cached_read_index. This is a "snapshot" of where the Reader was last time we checked.
Logic: As long as my next_write isn't bumping into my cached_read_index, I don't care where the real Reader is. I assume the queue is safe.
Benefit: I only pay the "Bus Traffic Tax" when I think I'm full.
Let's say we have a Queue of Size 12.
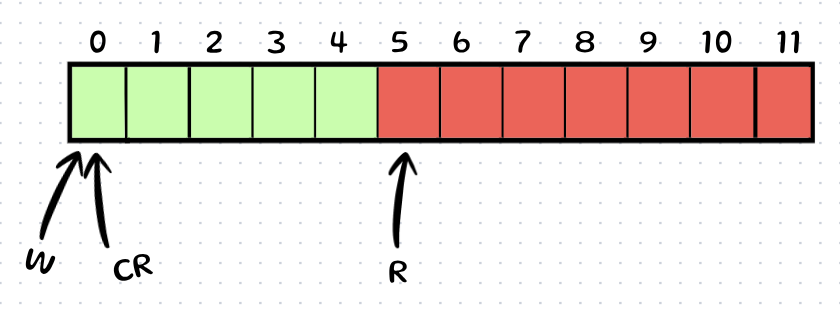
Real Reader (R) is actually at index 5.
Writer (W) is at index 0.
Writer's Cached Read (CR) starts at 1 (Initialized state so as to keep the 0th index as sacrificial slot at start).
Step-by-Step Execution:
Writer wants to write to Index 0.
It calculates W position = 0.
Let's look at the "Full" check. (W(0) + 1) == CR(1)? Yes, means that according to the last(initial) read position the 0th index would be the sacrificial slot.
Rule Of Thumb : a request will be transmitted into the CPU bus to get the current positon of read index, whenever (W + 1)%size = (CR).
Initially, CR is 1. So Writer thinks: "Uh oh, (W+1) might hit CR. I better check the real Reader."
BUS SNOOP: Writer fetches Real R. It gets 5.
Writer updates CR = 5.
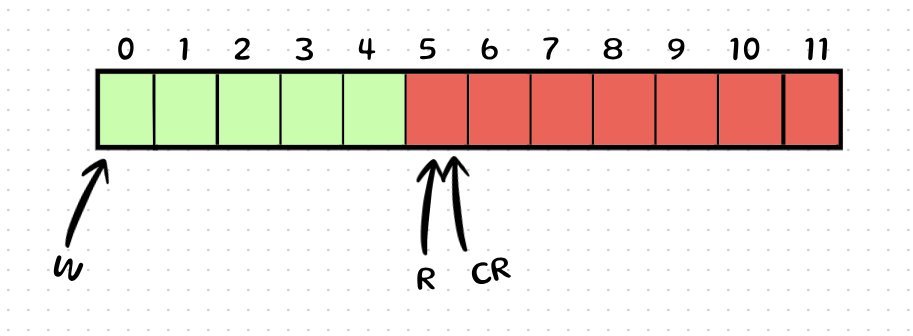
Writer writes to Index 0.
Writer wants to write to Index 1. next_write = 2. Does 2 == CR (5)? No. → Action: Write immediately! (Zero Bus Traffic).
Writer wants to write to Index 2. next_write = 3. Does 3 == CR (5)? No. → Action: Write immediately! (Zero Bus Traffic).
Writer wants to write to Index 3. next_write = 4. Does 4 == CR (5)? No. → Action: Write immediately! (Zero Bus Traffic).
Writer wants to write to Index 4. next_write = 5. Does 5 == CR (5)? YES!
Writer thinks: "Shoot, I think I'm full. My old data says the Reader is at 5. But maybe he moved?"
BUS SNOOP: Writer fetches Real R.
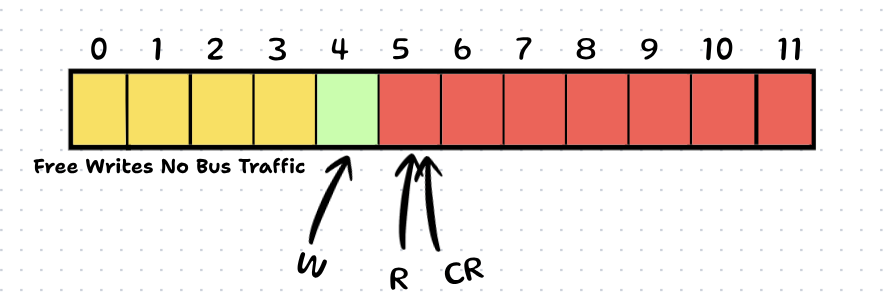
Scenario A: If Real R is still 5, the queue is truly full. Writer waits.
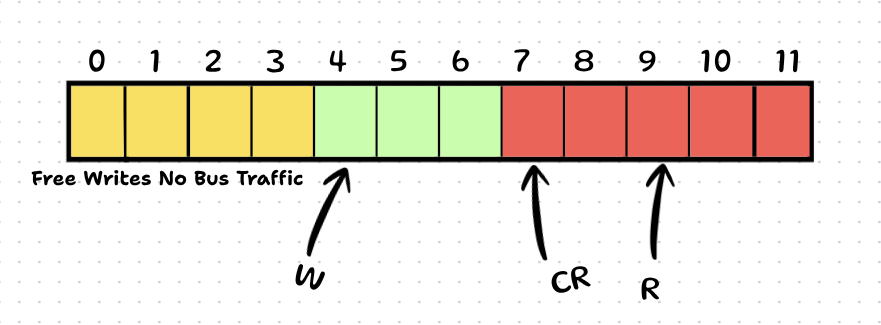
Scenario B: If Real R has moved to 7, Writer updates CR = 7 and continues writing now say R increments further and goes at 9, CR remains at 7 and we get free writes untill W points to 7.
The Result: Instead of checking the bus 5 times (for indices 0, 1, 2, 3, 4), we checked it once (at index 0) and then did 4 writes for "free".
Just like the Writer doesn't need to check for space constantly, the Reader doesn't need to check for data constantly.
The Logic: The "Data Zone"
The Reader is at index R. The Writer is at index W. The Reader's #1 rule is: "Do not read if the queue is empty." Mathematically, "Empty" means: R == W.
In the naive implementation, the Reader asks the Writer: "Did you write anything new?" (write_index.load()) before every single read. This is wasteful. If the Writer dropped 100 items into the queue, why ask "Is there data?" 100 times? You should ask once, see 100 items, and consume them all in one go.
The Solution: Shadow Indexing The Consumer maintains a local variable: cached_write_index. This is a snapshot of where the Writer was last time we checked.
Logic: As long as my read_index hasn't caught up to my cached_write_index, I know for a fact there is valid data waiting for me. This creates a "Data Zone" a stretch of the buffer that we know contains valid messages.
The Producer maintains a shadow index of the Consumer, and the Consumer maintains a shadow index of the Producer.
This lazy pointer optimization reduces the Bus traffic essentially a hundredfold. To achieve this, we keep 2 shadow indices:
The read shadow index lies inside the Producer to keep track of the last known position of the Consumer. Similarly, the lazy write shadow index lies inside the Consumer to keep track of the last known position of the Producer.
The Math of Reduction
Before: 1 Operation = 1 Bus Check. Traffic Load: 100%.
After: 1 Bus Check allows for Capacity - 1 operations in the best case.
If your Ring Buffer size is 1024, you check the bus 1 time and You perform 1023 operations in silence (pure L1 cache hits), reducing traffic load to ~0.1%.
The Result: We have effectively reduced the coherence traffic on the CPU Ring Bus by 99.9%. By silencing the constant chatter between cores, we freed up the bandwidth for what actually matters: moving the data itself.
Benchmarks
rituraj12797@bellw3thers-pc:~/.../build$ ./lockfreequeue
Main Thread Executing
Thread [ std writer ] pinned to Core 3
Thread [ std reader ] pinned to Core 4
================== BENCHMARK PERFORMANCE FOR std::queue + mutex ==================
WRITE LATENCIES
P50 : 82
P99 : 1436
P99.999 : 23868
READ LATENCIES
P50 : 54
P99 : 1533
P99.999 : 35241
====================================================================================
Thread [ writer to lf_queue ] pinned to Core 6
Thread [ reader to lf_queue ] pinned to Core 5
====================== BENCHMARK PERFORMANCE FOR LF_queue ========================
WRITE LATENCIES
P50 : 17
P99 : 24
P99.999 : 6031
READ LATENCIES
P50 : 16
P99 : 18
P99.999 : 501
Insights
We Increased our write throughput by 5x in push (9M/seconds → 55M/seconds) and pop(8 M/seconds → 40M/seconds) our optimized LF_queue isn't just "faster" it’s essentially playing a different sport while the standard mutex + std::queue approach spends most of its time in locking, unlocking, our implementation achieves a consistent throughput of ~55M reads/second and ~40M Writes/S for 99% of the time.
One more thing, we drastically reduced the Jitter/latency Spread (p50 → p99) from 50ns(earlier) to ~6-8 ns now, why this matter ??.
Because in low latency environments, a high average speed is useless if you have "jitter" (those huge P99 spikes). It's like having a code that runs fast but randomly slows down in between. By dropping the jitter using lazy pointers and cache alignment, we ensure that the system doesn’t randomly decide to take a nap while a critical packet is waiting.
But There Is one Major Win Which The benchmark Does Not Show.
It is the sheer amount of screaming we stopped on the CPU Bus, mathematically speaking, let's look at what we actually achieved. Suppose we have a buffer with a capacity of 1,000,000 entries. Let's say the Reader is slightly slow (or stopped), and the Writer manages to push 10,000 items before it finally bumps into its cached_read index.
In the Original Naive Code: The Writer is a nervous wreck. It asks, "Are we full yet?"( Every Request costs say 1 bus transaction, even though it costs more we will consider 1 for simplicity) before every single write. Bus Requests ~ 10,000
But with shadow indices: The writer is chill. It checks the map once, sees 10,000 freely of write-able blocks, glides through it. It only checks the bus once when it thinks it might have hit the limit. Bus Requests = 1
Depending on the chunk size, we managed to reduce bus traffic by:
Percentage Reduction = ((10,000 - 1) / 10,000) * 100
We reduced the noise by 99.99%.
It took a bit of bit-shuffling and some "lazy" logic, but when being lazy results in saving 10,000 trips across the CPU bus, I’m happy to call it an architectural masterpiece.
Final Code
Before you assume I code using AI let me make it clear, I make a lot of typos so for that obvious reason I have used Agentic-AI to write gramatically correct comments(only) for me, code is purely written by me.
#include<iostream>
#include<vector>
#include<atomic>
#include<thread>
#include "imp_macros.h"
namespace internal_lib {
template<typename T>
class LFQueue final {
// 'final' keyword prevents inheritance, allowing the compiler to
// devirtualize function calls → performance gains.
private :
alignas(64) std::atomic<size_t> next_index_to_read = {0};
alignas(64) size_t lazy_write = {0};
std::vector<T> store_;
alignas(64) std::atomic<size_t> next_index_to_write = {0};
alignas(64) size_t lazy_read = {0};
public :
size_t buffer_size = 2;
size_t capacity_mask = buffer_size - 1; // the mask we will use to wrap
explicit LFQueue(std::size_t capacity ){
size_t target_size = capacity;
if(target_size < 50 * capacity) target_size = 50 * capacity; // multiplier logic
buffer_size = 2;
while(buffer_size < target_size) {
buffer_size *= 2;
}
capacity_mask = buffer_size - 1;
store_.resize(buffer_size);
}
LFQueue() = delete;
LFQueue(const LFQueue&) = delete;
LFQueue(const LFQueue&&) = delete;
LFQueue& operator = (const LFQueue&) = delete;
LFQueue& operator = (const LFQueue&&) = delete;
T* getNextWriteIndex() noexcept {
// Check if wrapping around hits the lazy pointer
if(((next_index_to_write + 1) & capacity_mask) == lazy_read) {
// We hit the shadow pointer. Check the REAL read index.
if(((next_index_to_write + 1) & capacity_mask) == next_index_to_read) {
return nullptr; // Actually full
}
// Updated our shadow pointer
lazy_read = next_index_to_read;
}
return &(store_[next_index_to_write]);
}
auto updateWriteIndex() noexcept {
// No contention here as our queue is SPSC (Single Producer Single Consumer)
// Only one writer, so only it will update the write index
if( ((next_index_to_write + 1) & capacity_mask) == lazy_read) {
lazy_read = next_index_to_read;
internal_lib::ASSERT(((next_index_to_write + 1) & capacity_mask) != lazy_read ," Queue full thread must wait before further writing");
}
next_index_to_write = ((next_index_to_write + 1) & capacity_mask);
}
T* getNextReadIndex() noexcept {
// If the consumer consumed all the values and is now pointing to the
// same index as the shadow write index...
if(next_index_to_read == lazy_write) {
// Check the REAL write index.
if(next_index_to_read == next_index_to_write) {
return nullptr; // Queue is empty
}
lazy_write = next_index_to_write;
}
return &(store_[next_index_to_read]);
}
auto updateNextReadIndex() noexcept {
if(next_index_to_read == lazy_write) {
lazy_write = next_index_to_write;
internal_lib::ASSERT(next_index_to_read != lazy_write," Nothing to consume by thread ");
}
next_index_to_read = ((next_index_to_read + 1) & capacity_mask);
}
};
};
*/
A fun fact.
As always here's a interesting fact....Your CPU is a very smart gambler(Like Hakari from JJK.) when it comes to predicting outcomes of branch instructions thanks to it's Hardware Branch Predicting Unit.